一次使用 Manticore Search 取代 MongoDB 的經驗
2024-08-26
前言
四年前疫情的時候,因為比較空閒,便做了一個小小的 indexing 網站,四年過去,如今已經變成有一定流量的網站了
 Cloudflare一個月的數據
Cloudflare一個月的數據
可是原本因為方便而使用的 MongoDB 便成為了網站的瓶頸,再加上省錢把所有東西放在同一台 VM 內,令伺服器的 CPU 在 peak hours 長期處於 100% 的狀態,最嚴重時每兩分鐘就要重啟一次的伺服器,所以決定花一個週末 review 並且解決 backend 的結構問題
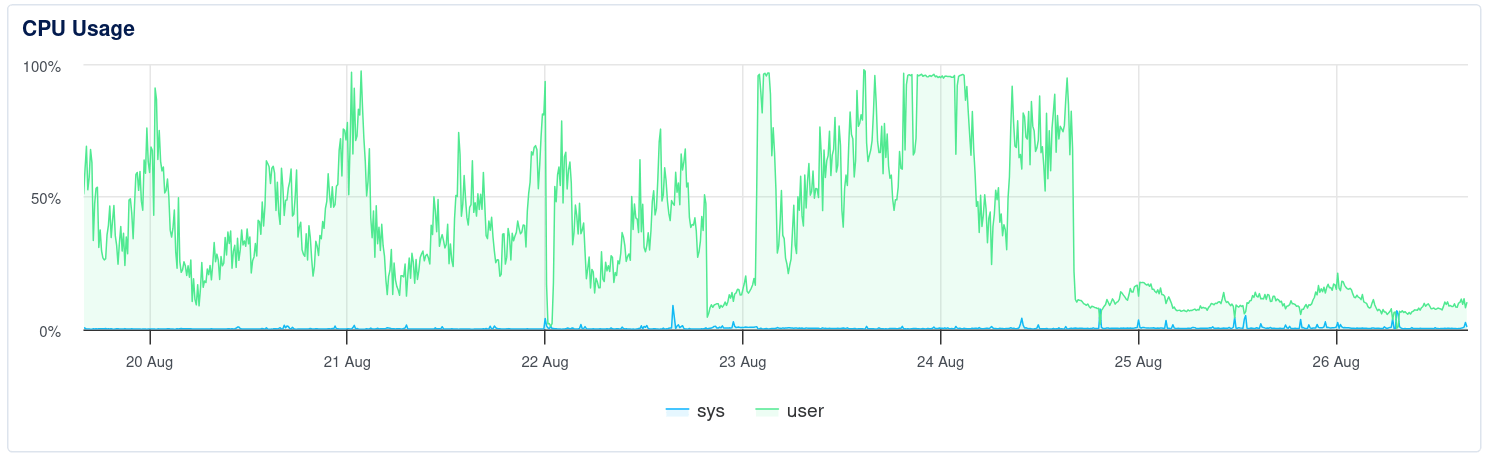 解決前/後的CPU使用率
解決前/後的CPU使用率
CPU 100% 的原因
造成 CPU 滿載的主因是使用了類似 SQL 的 LIKE 的 query,而在 MongoDB 我則用了 regex 查詢
db.movie.find({
name: new RegExp(text, "i")
});但根據 MongoDB 的官方文件顯示 index 對 case insensitive regex 並沒有作用的,所以這些 query 會對資料庫造成很大的負擔,然後一直卡在運算中並佔用著資源,同時有大量新的請求導致資料庫一直無法處理完成
為何不用 full text search (FTS)?
$text 是 MongoDB 的 FTS 方案,先撇除我的資料需要中英夾雜搜尋的部份,即使是中文搜尋用已經出問題了,因為 CE 版本並不支援中文語法,意思是假如標題是 鬼滅之刃劇場版 無限列車篇,而 英文語句用空白格作為分隔,所以必需使用以下 query 才能搜尋到資料
db.movie.find({
$text: {
$search: "鬼滅之刃劇場版"
}
})下面這條便無法取得結果
db.movie.find({
$text: {
$search: "鬼滅"
}
})Atlas search
如果是經 Atlas 管理的用戶可以嘗試使用 atlas search,它應該支援中文語法吧,至於多語言混合查詢就不太清楚了,atlas 的定價不在我的考量範圍以內,所以沒有花時間測試
第一次嘗試 postgreSQL
其實在半年前我便打算用 postgreSQL 完全取代 MongoDB,而且已經接近完成 backend 的重寫,但最終因為各種 migration 難題和性能沒有想象中好而閣置了,但當時還是源用 regex 的方法查詢,所以這次有機會便換成 FTS 再試一下
成功但存在性能隱憂
經過一翻嘗試,不但成功中文搜尋,而且中英混合多語言搜尋也能做到
SELECT title
FROM movie
WHERE to_tsvector(name) @@ to_tsquery('鬼滅 & engdub');可惜單是執行這句 query 便花了5秒左右,不計算 concurrency 下比 MongoDB 還要慢,大概是因為沒設定語言的原因吧,雖然我覺得可以再優化一下,但感覺上不太值得花時間在這地方,因為我也沒有打算完全取代 MongoDB
決定使用 Manticore Search
Manticore Search is an open-source database that was created in 2017 as a continuation of the Sphinx Search engine.
由於工作關係以前有使用過Elasticsearch(ES),速度是無話可說,但 JVM 的成本和複雜的設定讓我不得不放棄 self-hosting,所以一直也在找替代品,而這次終於找到了 Manticore Search 這個用 C++ 開發、打著 ES alternative 的旗號的 search engine
設定意外地簡單
以往使用 ES 的時候,複雜的安裝和嚴格的 schema 十分勸退,而 Manticore 不但安裝容易,還可以透過 sql client 或是 http 等不同方法直接建立 table,也不需要額外加甚麼 index,只需要 data type 是 text 便能支援 FTS 了
CREATE TABLE movies(name text) ngram_len='1' ngram_chars='cjk';
INSERT INTO movies(name) VALUES ('鬼滅之刃劇場版 無限列車篇 engdub');內建支援 cjk (中日韓文),輕鬆達到理想中的效果
SELECT * FROM movies WHERE MATCH('鬼滅 engdub');高效能、資源用量少
除了使用簡單,是否佔資源也很重要,最怕就是遇到 ES 這類需要大類 RAM 的引擎,而 Manticore 使用 C++ 編寫本身便需求比較少資源,亦似乎沒有多餘地使用 RAM,運行了三天用量也沒有遞增的跡象,之前其中一條需要5秒以上的 query、現在只需要0.2秒就完成了
 資料庫的CPU使用率
資料庫的CPU使用率
無法完全取代 MongoDB
跟 ES 一樣,這類 search engine 對於頻繁的讀寫並不是那麼友善和可靠,所以我只會在這邊儲存比較靜態的部份,主要資料還是會保留在 MongoDB
後記
這次把一個資料庫拆分成 general purpose 和 search engine 兩項,雖然聽起來比以前複雜了,但因為把資源分散的關係,實際進行 dev ops 的時候反而輕鬆不少
而且現在改動搜尋的部份也不用太害怕會影響到其他程序了,開發時間也比預期快了許多,最終只用了不夠兩天便完成了整個重寫和測試,對於一個很久沒碰的程式來說,已經是超額完成了
即使在一個比較簡單的項目,適量的增加複雜性從而提高彈性、看來也是一個不錯的 practice 呢~