Kindle手機版不支援Word Wise,所以我用自己方法做了一個 (ಠ_ಠ)
2018-02-23
With Word Wise, you can see simple definitions and synonyms displayed inline above more difficult words while you read.
以前因為想方便看書買了 Kindle,無意中發現有 Word Wise 這功能,之後就開始試著多看一點英文書,用久了又覺得 Kindle 帶出外也沒想像中方便,搜尋了一下發現竟然沒有ios 或是雲端版本,然後就想自己做一個看看 ⋯
 我的 Kindle Paperwhite 3 ヽ(=^・ω・^=)丿
我的 Kindle Paperwhite 3 ヽ(=^・ω・^=)丿
其實 Android 也是有支援 Word Wise 的,但 Word Wise 本來也不是支援所有書本的,尤其是 Ulysses 這類老書(雖然翻譯了我也看不懂•_ゝ•),所以這也不是換隻 Android 手機就能解決的問題
這些是我想要的 ⋯
- 免費! d(`・∀・)b
- 可以閱讀 Epub
- 可以在網頁上閱讀
- 可以滾動式閱讀(我討厭換頁)
- 自動翻譯難字
- 按鍵翻譯單字
簡單來說,需要驗證的東西就是讀 EPUB、分頁和找難字(沒錯,滾動式閱讀也是需要分頁的),開始的時候我就直接跳過了找難字這個部分,最壞打算就把 stop words 以外的英文單字全都翻譯算了!
DAY1
讀 EPUB
感謝 NPM,已經有人寫了 epub 讀取模組了,就是這個 epub,雖然我覺得這模組是有缺憾啦,但總比從 0 開始來的好,只是到後來發現 epub 不就只是個 zip 嗎?
分頁和增加行距
最初的想法就是根據設備大小改變顯示的頁數,例如電腦看是 100 頁,手機則是 600 頁之類的,然後為了留一點空間給 Word Wise,所以還要考慮行距的問題,做法如下:
- 讀取 epub,獲得
Chapters! - 再用 Canvas 的
measureText()功能計算字串長度,把Chapters拆分成數十至數百行,每行都是剛好或接近螢幕的寬度 - 然後每行都用
<p>包著,再在它們之間插入一行空白的段落,所以100 行的章節,便會產生一個 200 行的 Array,很蠢的做法!
經過第一次試驗,感覺大概像這樣 ⋯

HTML 碼就長成這個樣子 ⋯
<p></p>
<p>
Harry heard from Hogwarts one sunny morning about a week after he had arrived
at
</p>
<p></p>
<p>
the Burrow. He and Ron went down to breakfast to find Mr. and Mrs. Weasley and
Ginny
</p>
<p></p>
<p>
already sitting at the kitchen table. The moment she saw Harry, Ginny
accidentally
</p>
...
DAY2
加入翻譯
再來就是選擇翻譯的工具,一開始我選擇用 cc-cedict,它是一個免費、可以離線使用的「中英」字典,這裡要留意一下「中英」即是由中文翻譯做英文,所以是以 中文作為 key,問題就來了 ⋯
我們只能從 /{word}/ 內拆成 key,下面例子我們可以拆出 {apple: "蘋果"} 這個組合。
蘋果 苹果 [ping2 guo3] /apple/CL:個|个[ge4],顆|颗[ke1]/
問題是這些一整句的就不能用了 ⋯
蘊藏 蕴藏 [yun4 cang2] /to hold in store/to contain (untapped reserves etc)/
而且它畢竟沒有 Google Translate 般強大的 ML 功能,所以可想而知翻譯出來的關聯字詞我們是沒辦法用程式判斷哪個才是準確的,看看下面災難級的例子就不言而喻了 ⋯
伙食 伙食 [huo3 shi2] /food/meals/
口實 口实 [kou3 shi2] /food/salary (old)/a pretext/a cause for gossip/
吃食 吃食 [chi1 shi5] /food/edibles/
粻 粻 [zhang1] /food/white cooked rice/
食物 食物 [shi2 wu4] /food/CL:種|种[zhong3]/
飯 饭 [fan4] /food/cuisine/cooked rice/meal/CL:碗[wan3],頓|顿[dun4]/
飯菜 饭菜 [fan4 cai4] /food/
飯食 饭食 [fan4 shi2] /food/
餇 餇 [tong2] /food/
餐點 餐点 [can1 dian3] /food/dish/meal/
饋 馈 [kui4] /food/to make a present/
饌 馔 [zhuan4] /food/delicacies/
饎 饎 [chi4] /food/to cook/
不過在沒有選擇的情況下(因為要免費 ⋯)就先用用看吧,反正就只是驗證階段,所以我就隨機抽出一些單字再用 cc-cedict 翻譯上去。
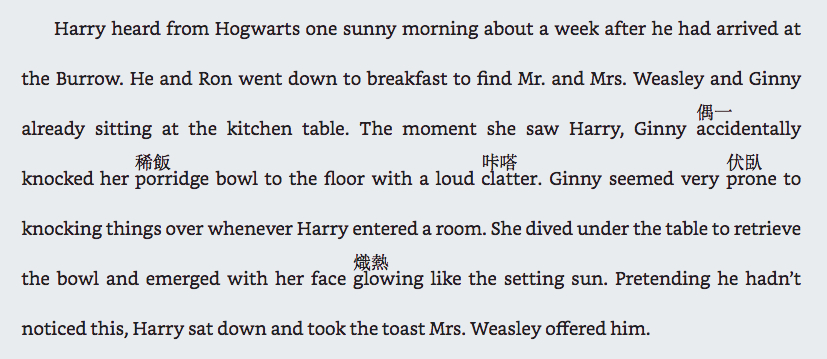
看上去還算不錯,做法大概就是在空白的那行 <p> 插入包著翻譯的 <span>,就像這樣 ⋯
<p><span style='position: absolute; left: 600px;'>偶一</span></p>
<p>already sitting at the kitchen table. The moment she saw Harry, Ginny accidentally</p>
...
翻譯的位置一樣是用 Canvas 的 measureText() 計算的。
DAY3
找‧難‧字!
我對這部分是最沒有信心了,畢竟「難」的定義是因人而異的,從技術上來看就覺得需要大量使用者的資料才能分析出那些所謂的「難字」,不過在經過一番研究以後看到有人建議使用「word frequency」計算,又讓我看到了一點曙光,至於來源方面 Amazon 是無望了,所以就找一了下 Google 的,讓我找到了這個 Ngram Viewer
這是 Google 長年累月掃描海量的 Google Books 得出來的字詞出現率數據,我相信這是一個不錯的工具,如果那不是一個佔了十幾 GB 的 1-grams 的數據 ⋯ 之後我找到很多不同的來源,最後選擇使用這個 Washington University 提供的 English Lexicon Project,容量小比較有善又可靠 ⋯
糾結於難字
我下載了最簡單的版本,是一個 CSV 檔案,非常好!
"Word","Length","Freq_HAL"
"a","1","10610626"
我參考了很多算式,但是卻找不到讓我滿意的結果,短的字不一定難,常出現的字也不代表容易,例如 sunny 就只出現了四千多次,但不算難是吧?不過,用出現率總比長度準確,可惜結果是 ⋯ 不行!由於字庫的問題,有很多我覺得很難的字都沒有出現,怎麼辦?
DAY4
找‧簡‧單‧字!
這故事告訴了我逆向思考的重要性,既然找不到難字,那就把簡單的字排除掉,這樣就不存在字庫缺字的問題了!
我很快就把這概念加到程式裡,出現次數的 threshold 我調整了幾次,最後用 Freq_HAL < 20000 過濾了簡單的字,然後翻譯其餘的生字,但結果怎麼跟之前差不多?!我想大概是字典出了問題 ⋯
DAY5
改善分段方法
我就說過之前的分段用了一個很蠢的方法,為了加入翻譯便插入一倍的 <p></p>,而且強行分段有很大機會變成「爛 UI」,畢竟不能太過依賴 Canvas 的計算。

經過修改後,所有的 <p> 都改成 <span>,這些字串就會自動填滿段落了。
<span
>Harry heard from Hogwarts one sunny morning about a week after he had arrived
at
</span>
<span
>the Burrow. He and Ron went down to breakfast to find Mr. and Mrs. Weasley
and Ginny
</span>
<span
>already sitting at the kitchen table. The moment she saw Harry, Ginny
accidentally</span
>
再來就是修改 CSS 的 line-height 加點行距就好了,至於翻譯,就用 CSS 的 :before 功能,但首先雖要修改一下 html,把難字用 <span> 包起來。
<span
>... she saw Harry, Ginny
<span class="word word-accidentally" data-before="偶然"
>accidentally</span
></span
>
修改一下 CSS,翻譯就會顯示在 accidentally 的上方了,★MAGIC★!
.word:before {
content: attr(data-before);
position: absolute;
top: -30px;
left: 0;
width: 200px;
height: 0;
}
DAY6
解決翻譯問題 - 字典
不是說免費就沒好東西,但是這次免費的字典真的沒很大幫助,所以最後還是轉了使用一些翻譯的 API⋯
即時翻譯
項目來到了尾聲,只要加入即時翻譯,就可以填補了「偽 Word Wise」找難字的不足,所以我想盡可能弄得方便一點,想找翻譯?雙擊吧!

為甚麼不用單擊呢?因為之前是設計是把難字包在 <span> 內,所以我們要在點字的時候修改它的 html 碼,單擊相對較難做到這一點,而且用單擊也有可能造成不便。至於雙擊時,普遍瀏覽器都會選取目標字,運用這一點可以很容易取得並修改目標字詞的 html 碼,之後只要再進行一個簡單的 AJAX 請求就 OKAY 了!
END
追索到最初的想法,我是有考慮放到 App Store 之類的,後來越做越發現有很多版權上的問題,例如 EPUB、翻譯、word frequency 全部都跟版權有關,所以我想暫時還是當作學習用途吧,哈哈!而且 UI 也沒做到能讓人看的程度,倒不如把時間放到下個項目裡去算了~